Je možno využít i open-source verzi.
Pokud nemůžete instalovat, použijte portable verzi.
Při aktualizaci Javy je třeba ve Windows ručně aktualizovat cestu k Javě: „Upravit proměnné prostředí systému“ -> „Proměnné prostředí“ ->
JAVA_HOMEToto je návod pro práci s Pentaho Data Integration (PDI) – Kettle – zejména s vývojovým prostředím Spoon. Nejprve si přečtěte Obecné informace o PDI a dalších komponentách platformy Pentaho.
Od té doby, kdy byla firma Pentaho koupena korporací Hitachi, vývoj platformy Pentaho stagnuje a web platformy je zmatený. Původní autor PDI (Matt Casters) vytvořil Apache Hop, fork PDI, který má konečně elegantní architekturu a je intenzivně vyvíjen. Transformace PDI je možo do něj importovat. Nově funguje náhled dat na kliknutí, stejně jako v PDI.

Spoon.bat2)
Níže je seznam některých kroků (steps) transformací a dále totéž pro jobs (úlohy vytvořené z více transformací). Jsou zmíněny i triky a tipy, které mi nebyly z dokumentace zřejmé.
| Symbol | Název | Popis |
|---|---|---|
| | Text file input | Čtení textových souborů. Používat i pro soubory CSV (nikoliv CSV file input, který neumí zpracovat jednoduše celou složku). Pěkně umí fixed text. Pokud vyberu Number of header lines, tak budu asi potřebovat definovat sloupce ručně, protože uvažuje jen první řádek a ostatní vynechává. Nebo raději pro vývoj upravit záhlaví na jednořádkové a pro produkci použít původní soubory. |
| Jiné kroky umožňují načítat data z (a ukládat do) nejrůznějších databází, zdrojů (e-mail, lokální počítač, FTP, HTTP) a souborů (MS Excel, ESRI SHP, JSON, YAML, RSS, ZIP atd.) | ||
| | Text file output | Vytvoření textových souborů. Může definovat obrovskou length, díky které nahlásí chybu s pamětí – stačí smazat. |
| | Table output | Vkládání dat do SQL databáze. Obsahuje průvodce pro vytvoření připojení k databázi. Dále je třeba vybrat cílové schéma a tabulku v databázi. Dokáže také vrátit automaticky generované id záznamu. |
| | Microsoft Excel Writer | Ukládá data do dokumentu ve formátu Microsoft Excel. |
| | Filter rows | Filtrování dat řádků pomocí vybraných podmínek. Datový tok je dále rozdělen na dvě větve podle splnění/nesplnění podmínky. Pokud se mají řádky rozdělit do více než dvou větví, použij Switch-Case. |
| | Formula | Možno použít pro jednoduché výpočty (např.: sloupec_1 * sloupec_2), pro jednoduché logické podmínky či spojování řetězců. Mé příklady vzorců dole na této stránce. |
| | Calculator | Vytvoření nového pole pomocí předdefinovaných vzorců. Je rychlejší než Formula (o řádek výše), ale méně obecný. |
| | Group by | Umožňuje počítat hodnoty pro skupiny dat. V nastavení se vyberou sloupce, které definují skupinu. Počítat se může například průměr, suma, minimum, maximum atd. |
| | Select values | Vybírání, odstraňování a přejmenovávání sloupců. Umožňuje měnit datový typ, nastavovat délku textových řetězců, počty desetinných míst u reálných čísel a další formáty dat. |
| | Sort rows | Seřadí data podle vybraného sloupce nebo několika sloupců. Podle nastavení řadí vzestupně nebo sestupně. Zaškrtnutím Only pass unique rows? nevyřadí duplicity na základě řadících kritérií. Klíč je něco jiného. Proč? Teď mi to fungovalo!!! |
| | Replace in string | Nahradí vybrané znaky/slova v textových řetězcích. Lze použít regulárních výrazů nebo přímo vyhledávací funkce, kterou tato komponenta obsahuje. Nahrazení hledané části je možné za jiný textový řetězec, nebo za hodnotu některého ze sloupců. |
| | Split Fields | Rozdělí textový řetězec v jednom sloupci do více sloupců podle zvoleného oddělovacího znaku či textového řetězce. |
| | Stream lookup | Join: propojení dvou streamů (tabulek – např. číselníku) aniž by bylo třeba mít záznamy seřazené. |
| | Row Normaliser | Type field (název nového sloupce kategorií)Fieldname (vstupní záhlaví)Type (hodnoty výstupních kategorií)New field (výstupní záhlaví hodnot) – nefungovalo mi nastavit řádky různě |
| | Row denormaliser | Key označuje vstupní kategorie.The key field (název vstupního sloupce s kategoriemi),Group field (co identifikuje celý budoucí řádek – např. filename),Target fieldname = Key value (jednotlivé kategorie),Value fieldname (název vstupního sloupce s hodnotami)Více |
| | Set Variables | Nastav proměnnou. V ostatních transformacích je možno je volat jako proměnné i jako parametry. U parametrů je možno definovat implicitní hodnotu. Parametr může být definován např. pomocí proměnné, ale má i defaultní hodnotu, která se uplatní, pokud proměnná není naplněna. Dříve byla v PDI proměnná, později parametr. |
| | ETL Metadata Injection | Řízení transformací ze streamu. Pokud chci spustit s různými parametry, je třeba kombinovat s Transformation Executor (níže).Best practices. Matt Casters: Parse nasty XLS with dynamic ETL Na konci článku je příklad včetně zdrojových souborů. Alternativou je spustit transformaci v jobu a zaškrtnout Execute every input row – video. |
| | Transformation Executor | Spustí pro každý řádek novou transformaci. Předává proměnné, které se v odkazované transformaci volají ${takto}. |
| | Add Constants | Přidání jedné nebo více hodnot (konstant) do polí. |
| | Analytic Query | Možnost zohlednit předchozí/nadcházející hodnoty. Data musí být seřazena. Slouží k přístupu k datům v jiných řádcích. Můžeme tak data z několika řádků převést do jednoho řádku s několika novými sloupci. Data je možné seskupit podle vybraných sloupců, aby se slučovala pouze data, která mají něco společného. |
| | Concat Fields | Slučování více polí do jednoho. |
| | Copy rows to result | Zajišťuje převod dat do další transformace v rámci „jobu“. Pro vývoj netřeba spojovat jobem. |
| | Get data from XML | Načítá data z XML souborů. Je možné přímo zvolit datové typy vstupních dat a jejich formát (např. u desetinných čísel). Obsahuje funkci pro automatické načtení sloupců podle tagů v XML souboru. Pokud požadovaná vstupní data nejsou textem mezi počátečním a ukončovacím tagem, ale například atributem tagu, je nutné přidat je ručně. |
| | Get rows From result | Zajišťuje načtení dat z transformace, na kterou je tato napojena v rámci „jobu“. Aby bylo možné data načíst, musí být předchozí transformace obsahovat komponentu „Copy rows to result“. V této komponentě se pak nastavují názvy sloupců a jejich datové typy. Pro vývoj netřeba spojovat jobem. |
| | Umožňuje posílat email na předem definované adresy. Je nutné nastavit SMTP server, kterým může být například Gmail a ověření. Text emailu musí být také předem definovaný. K emailu je možné přidat přílohu, jejíž adresa (v souborovém systému) se nastavuje přímo v této komponentě. | |
| | Modified Java Script Value | Umožňuje vytvářet javascriptové výrazy. Ty mohou být použity například pro upravování textových řetězců (cesty k souborům …). Ale má i spoustu dalších použití. |
| | User Defined Java Expression | Vlastní výraz napsaný v jazyce Java. Mé příklady. |
| | Pentaho Reporting Output | Umožňuje vytvářet reporty, podle předem definované šablony vytvořené v PRD. Cesta k šabloně a k souboru, který má být z této šablony vytvořen, musí být dopředu definována. V nastavení komponenty se vybírá formát výstupního reportu (např.: PDF, HTML atd.). |
| | Unique rows | Odstraní duplicitní řádky. Nastavuje se sloupec, nebo sloupce, při jejichž shodné hodnotě u více řádků se zachová pouze první záznam. Před tímto krokem musí být data seřazena pomocí kroku Sort rows. |
| | Microsoft Access Input | Čte data ze souborů ve formátu Microsoft Access. |
| | Microsoft Access Output | Ukládá data do tabulky databáze Microsoft Access. |
| | Merge Join | Spojí řádky dvou načítaných vstupů pomocí vybraného klíče do jednoho výstupu. Vstupy musí být před spojením seřazeny podle vybraného klíče. |
| | Row flattener | Převod sloupce na řádek |
| | Add sequence | Inkrementace hodnot (indexace řádků apod.) |
| | XBase input | Čte soubory databázového typu dbf |
| | Get file names | Získá cestu/jméno ke všem souborům ve vybrané složce |
| | Regex evaluation | Vlastní regulární výraz. Mé příklady dole na této stránce: Regulární výrazy. |
| | Block this step until steps finish | |
| Dummy (do nothing) | Spojování větví; zobrazení výsledků (např. Filter rows) |
|
Další kroky jako doplňky pro PDI:
| Symbol | Název | Popis |
|---|---|---|
| | START | Možnosti spouštění jobu. |
| | Transformation | Spuštění transformace |
| | Success | Možné ukončení jobu. Ignoruje chyby a vynutí úspěšné ukončení jobu. |
| | Get a file with FTP | |
| | ||
| | Unzip file | |
| | Truncate tables |
Oficiální zdroj uvádí všechny kroky transformací a entries jobů.
Tomu v Apache Hop odpovídají transforms a actions.
Regulárních výrazů je více typů. Zde jsou uvedeny tak, jak fungují v PDI.
Tabulka Výběr vstupních souborů (regulární výraz odpovídá názvu souborů)
| Popis | Regulární výraz |
|---|---|
| Soubory s danou příponou | .*\.xlsx |
| Libovolné soubory | .* |
Soubory začínající na facts | facts.* |
Tabulka Výběr z textového řetězce
| Popis | Regulární výraz | Vstup | Výstup |
|---|---|---|---|
| Mezery a tabulátory | [ \t]{1,} | ||
| Mezi závorkami | .*\((.*)\).* | stanice: ČK (9 m n.m) | 9 m n.m |
| Po mezeře před závorkou | []* (.*) \(.* | stanice: ČK (9 m n.m) | ČK |
| Do znaku čárka, středník či tečka | ([^\s?:(?!;).]+).* | ||
| Do znaku čárka, středník či tečka apod. | ([^\s]+).* |
Tabulka Validace textového řetězce
| Popis | Regulární výraz | Detail |
|---|---|---|
| Validace čísla napsaného jako text s ne více než dvěma desetinnými místy | [+\-]?\d+(\,\d{1,2})? | s desetinnou čárkou |
[+\-]?\d+(\.\d{1,2})? | s desetinnou tečkou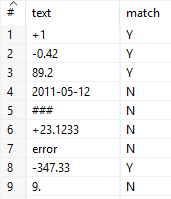 |
|
| 6 až 8 číslic | ^[0-9]{6,8}$ | Zdroj |
| Dvě verze téhož jména | (Bill|William) Turner | Zdroj již neexistuje |
| Jména políček v šachu např. A6 | [A-H][1-8] | Zdroj již neexistuje |
| Cokoliv začínající číslicí | [0-9].* | Skutečně? Ve „Filter Rows“ je to možno udělat přímo bez regulárních výrazů. |
| Číslo s desetinnou tečkou (může být i záporné) | ^-?(\d+\.\d*)$ | |
| Číslo s tečkou na konci | ^(\d+.)$ |
Zkopírovat hodnoty do prázdných polí na následucících řádcích. Jako je v Excelu Vyplnit dolů:
var novy_sloupec; if(existujici_sloupec === null) {} else { novy_sloupec=existujici_sloupec; }
Dokumentace, Dokumentace Hop
Názvy sloupců se zadávají v hranatých závorkách.
year([datum]) – Z plnohodnotného datumu v sloupečku datum vezme rok.
[rok]&"-"&[měsíc]&"-15" – Z textu odpovídajícímu roku a měsíci vytvoří datum (15. den)
IF(AND([nazev_veliciny]="souřadnice:"; [sloupec]="1");"x";"") – To jsem nepoužil, protože je to lepší udělat pomocí Lookup tabulky.
IF([x]>0;-1*[y];[x]) – Když jsou zamíchány souřadnice S-JTSK kladné a záporné.
IF([bottom_depth]>[predchozi];[predchozi];0) – Výpočet top_depth z bottom_depth. Sloupec predchozi se vypočítá pomocí Analytic Query.
${Internal.Entry.Current.Directory})Date Format Lenient, resp. Lenient number conversion, aby bylo rozpoznávání datumu resp. čísla dostatečně benevolentní.in, out), samostatně si uložit původní zdrojová data (složka ZD)Spoon.bat in a Windows environment nothing happens. How can I solve it?Spoon.bat file and:start javaw with only java.pause in the next line.simple-jndi, which contains a file named jdbc.properties. You should change this file so the JNDI information matches the one you use in your application server.
ROLDÁN, María Carina, 2017. Learning Pentaho Data Integration 8 CE : Third Edition. Packt Publishing. ISBN 978‑1‑78829‑007‑4.
JAVA_HOMEset-pentaho-env.bat – netřeba spouštět samostatně.